Syntactic Analyzer
One of the analyzes to help understanding the meaning of a text is to perform a syntactic analysis that can be done with the Syntactic Analyzer module. In the process, the text will be broken down into smaller parts and given certain labels. The Syntactic Analyzer module performs three analyzes carried out by the components: Tokenizer, Stemmer, and Part-of-Speech tagger (POS tagger).
This module is used by entering text either in the form of paragraphs or sentences and returning the results of the analysis.
Tokenizer
The Tokenizer is a component in the Syntactic Analyzer module that serves to cut text into a set of tokens (words) and/or sentences. The process of cutting the word is then called the term tokenization. Tokenization is the initial process of language processing. This Tokenizer is able to analyze data text with the following conditions:
- Handles the special cases contained in the General Guidelines for Indonesian Spelling (PUEBI), such as writing money (Rp50), writing titles (Dr.), and separating two or more different words not separated by spaces (Jokowi-JK, Anyer-Panarukan).
- Supports various types of text formats such as news or social media.
Illustration
-
Tokenize paragraph into sentences
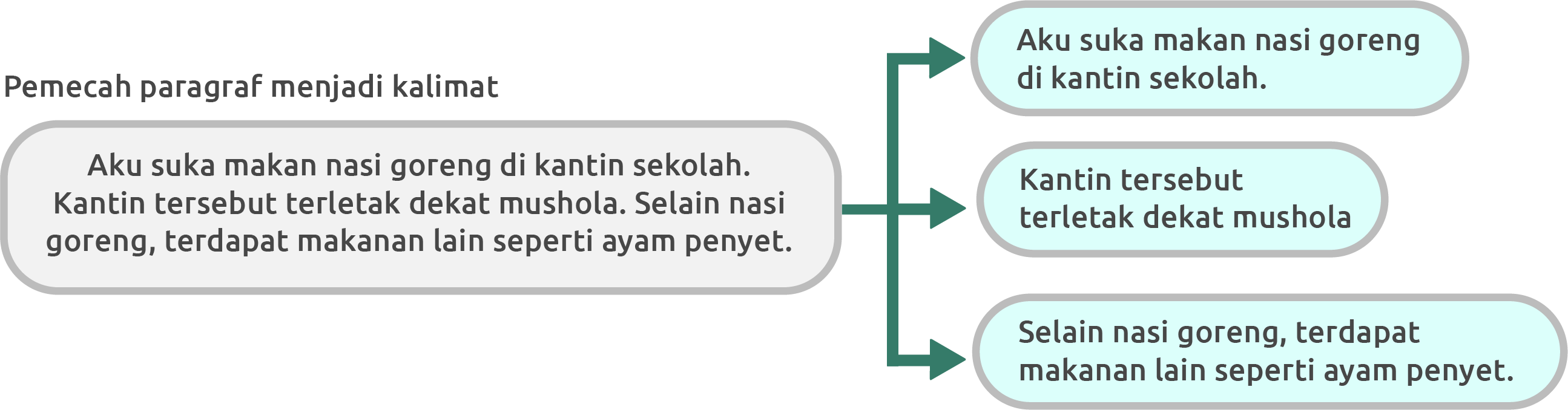
-
Tokenize sentence into words

Stemmer
The text analysis needed when understanding the meaning of a sentence is the identification of the basic word because words that have the same basic word will have the same meaning.
- Change passive sentences becomes active through changing their affixes. Example: "di" becomes "me" on "dibunuh" becomes "membunuh".
- Increase the relevance of search engine results on a site by matching search keywords that have been processed by the Stemmer API.
Illustration

Part-of-Speech Tagger
In Indonesian, each word occupies a specific class of words that have different functions in a sentence structure. Word classes are needed to help process language automatically at a higher level, such as knowing the structure and meaning in a sentence. POS Tagger is used to obtain various types of word classes, including nouns, pronouns, verbs, adjectives, prepositions, numbers, adverbs, punctuation, and so on. The output from this module is in the form of a word class for each word contained in the input text, either in the form of articles or sentences.
Illustration

Request Method
POST
Request URL
1 | |
Request Header
| Key | Data Type | Description | Value |
|---|---|---|---|
| Content-Type | string | Media type of the body sent to the API. Only Support 'application/json' | application/json |
| x-api-key | string | API Key Acquired from Prosa API Console | [YOUR_API_KEY] |
Request Body
The request body accepts the following parameter(s) in JSON format.
| Parameter | Data Type | Description | Auto | Required |
|---|---|---|---|---|
| text | string | text to be processed | True | |
| granularity | enum | part-of-speech types granularity | 'fine_grained' | False |
Granularity Enums
Part-of-speech tags granularity.
| Granularity | Description |
|---|---|
| coarse | 16 classes based on universal dependencies pos tags. |
| fine_graned | 28 classed based on INACL (Indonesia Association of Computational Linguistics) convention. |
Example
Sample Request (JSON)
1 2 3 | |
Sample Response (JSON)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 | |
Fine Grained POS Tags
Based on INACL (Indonesia Association of Computational Linguistics) convention.
| Name | Code | Example | Description |
|---|---|---|---|
| Adjective | ADJ | biru, sakit, gelisah, cerdas, cantik, panjang, ordinal non-kuantitatif: pertama, kedua, ketiga (example: juara pertama, abad ke-17) | Adjectives are words that typically modify nouns and specify their properties or attributes |
| Adverb | ADV | sangat, enggan, harus, mesti, agak, hanya, semakin | Adverbs are words that typically modify verbs for such categories as time, place, direction or manner. |
| Articles | ART | para, si, sang, hang, ini, itu | Articles are words that modify nouns or noun phrases and express the indefinite reference of the noun phrase in context. |
| Coordinative Conjunction | CCN | dan, atau, tetapi | A coordinating conjunction is a word that links words or larger constituents without syntactically subordinating one to the other and expresses a semantic relationship between them. |
| Subordinative Conjunction | CSN | jika, meskipun, walaupun | A subordinating conjunction is a conjunction that links constructions by making one of them a constituent of the other. |
| Interjection | INT | aduh, astaga, wah, aduhai, nah, astaga | An interjection is a word that is used most often as an exclamation or part of an exclamation. |
| Quantifiers | KUA | sesuatu, semua, beberapa, berbagai, sebagian, segenap, masing-masing, segala | Quantifiers are words that modify nouns or noun phrases and express the definite reference of the noun phrase in context. |
| Negation | NEG | tidak, bukan, tak, enggak | Negation word are words used to express the contradiction or denial of something |
| Noun | NNO | buku, mobil, malaikat, pikiran | Nouns are a part of speech typically denoting a person, place, thing, animal or idea. |
| Proper Noun | NNP | Jakarta, Indonesia, Burhan Silalahi | A proper noun is a noun (or nominal content word) that is the name (or part of the name) of a specific individual, place, or object. |
| Numeral | NUM | satu, dua, sebuah, pertama | A numeral is a word, functioning most typically as a determiner, adjective or pronoun, that expresses a number and a relation to the number, such as quantity, sequence, frequency or fraction. |
| Preposition | PPO | di, ke, dari, tentang | Adposition is a cover term for prepositions and postpositions. |
| Interrogative Pronoun | PRI | apa, siapa, bagaimana | Interrogative Pronouns is pronouns used to replace something that is a question in a question sentence. |
| Cliticized Pronoun | PRK | mu, ku, nya | Cliticized Pronoun is a pronoun that is word morpheme |
| Pronoun | PRN | saya, anda, kamu, sesuatu, seseorang, itu, ini | Pronouns are words that substitute for nouns or noun phrases, whose meaning is recoverable from the linguistic or extralinguistic context. |
| Relative Pronoun | PRR | yang, tempat | Relative Pronouns are words that can be used to replace the main part and/or link it with it’s explanation. |
| Particle | PAR | pun, per, lah, toh, kah | Particles are function words that must be associated with another word or phrase to impart meaning and that do not satisfy definitions of other universal parts of speech (e.g. adpositions, coordinating conjunctions, subordinating conjunctions or auxiliary verbs). |
| Punctuation | PUN | ., ?, !, ", /, -, ; | a sign used to separate various parts of a written language unit (words, phrases, and sentences) and in some cases can affect the meaning of the language unit. |
| Character Symbols | SYM | Rp, $, Ω, ° | A symbol is a word-like entity that differs from ordinary words by form, function, or both. |
| Tense, Aspect, Modality, Evidentiality | TAME | telah, akan, bakal, sudah, sedang, lagi, masih, pernah, ingin, harus, perlu, boleh, pasti, tampaknya | a group of words that change the context of the tense, aspect, modality, or evidentiality of a predicate. |
| Intransitive Verb | VBI | duduk, menangis, bergembira, percaya | An intransitive verb does not have an object. |
| Transitive Verb | VBT | membaca, menyirami, membelikan | A transitive verb is one that is used with an object: a noun, phrase, or pronoun that refers to the person or thing that is affected by the action of the verb. |
| Linking Verb | VBL | adalah, ialah, merupakan, menjadi | An auxiliary is a function word that accompanies the lexical verb of a verb phrase and expresses grammatical distinctions not carried by the lexical verb, such as person, number, tense, mood, aspect, voice or evidentiality. |
| Passive Verb | VBP | dipukul, dipenuhi, disembuhkan | Passive Verb is a verb where it’s subject is the patient. |
Coarse POS Tags
Based on universal dependencies pos tags.
| Name | Code | Example | Description |
|---|---|---|---|
| Adjective | ADJ | biru, sakit, gelisah, cerdas | Adjectives are words that typically modify nouns and specify their properties or attributes. |
| Adposition | ADP | di, ke, dari, tentang, untuk | Adposition is a cover term for prepositions and postpositions. |
| Adverb | ADV | enggan, agaknya, masih | Adverbs are words that typically modify verbs for such categories as time, place, direction or manner. |
| Coordinating Conjunction | CCONJ | dan, atau, tetapi, baik | A coodinating conjunction is a word that links words or larger constituents without syntactically subordinating one to other and expresses a semantic relationship between them |
| Determiner | DET | sesuatu, semua, beberapa | Determiners are words that modify nouns or noun phrases and express the reference of the noun phrase in context. |
| Interjection | INTJ | aduh, astaga, wah, maaf | An interjection is a word that is used most often as an exclamation or part of an exclamation |
| Noun | NOUN | buku, mobil, malaikat, pikiran | Nouns are a part of speech typically denoting a person, place, thing, animal or idea. |
| Numeral | NUM | satu, dua, sebuah, kedua | A numeral is a word, functioning most typically as a determiner, adjective or pronoun, that expresses a number and a relation to the number, such as quantity, sequence, frequency or fraction. |
| Particle | PART | pun, per | Particles are function words that must be associated with another word or phrase to impart meaning and that do not satisfy definitions of other universal parts of speech (e.g. adpositions, coordinating conjunctions, subordinating conjunctions or auxiliary verbs) |
| Pronoun | PRON | saya, anda, seseorang | Pronouns are words that substitute for nouns or noun phrases, whose meaning is recoverable from the linguistic or extralinguistic context. |
| Proper Noun | PROPN | Jakarta, Indonesia, Burhan Silalahi | A proper noun is a noun (or nominal content word) that is the name (or part of the name) of a specific individual, place, or object. |
| Subordinating conjunction | SCONJ | jika, sejak, meskipun | A subordinating conjunction is a conjunction that links constructions by making one of them a constituent of the other. |
| Symbol | SYM | ? . ! - | A symbol is a word-like entity that differs from ordinary words by punctuation, form, function, or both. |
| Verb | VERB | duduk, membaca, dipenuhi, ada | A verb is a member of the syntactic class of words that typically signal events and actions, can constitute a minimal predicate in a clause, and govern the number and types of other constituents which may occur in the clause |
Free trial
Are you interested in our API? Click the button below and get your free trial now.

Version History
Below is the version history of our Syntactic Analyzer API.
| Version | F1 | Test Data |
|---|---|---|
| 1.0 | 96.13% | 10,890 token |
Questions?
We do our best to make this documentation clear and user friendly, but if you have unanswered questions, please send email to support@prosa.ai.